У индексов есть две задачи: соблюдать выполнение первичных ключей и уникальных ограничений, и увеличивать производительность. Стратегия по созданию индексов сильно влияет на производительность приложения. Нет четкого ограничения кто ответствене за создание индексов. Когда бизнес-аналитики составляют бизнес-требования к системе которые будут выполнены как создание ограничений – они влияют на индексы. Администратор будет наблюдать за выполнением запросов и давать рекомендации по созданию индексов. Разработчик именно тот кто лучше всех понимает что происходит в коде и природе данных – тоже влияет на стратегию создания индексов.
Почему индексы необходимы
Индексы это часть механизма ограничений (constraint). Если столбец (или группа столбцов) помечены как первичной ключ таблица, то каждый раз когда вставляется строка в таблицу, Oracle необходимо проверить что не существует строки с такими значениями. Если у таблицы нет индекса дял столбцов – единственный способ проверить это это вычитать всю таблицу. Это может быть приемлимо если в таблице всего несколько строк, но дял таблиц, содержащих тысячи миллионов (или миллиардов) строк это займёт очень много времени и неприемлимо. Индекс позволяет практически мгновенно получить доступ к значениям ключа и проверка на существование происходит моментально. Когда определяется первичный ключ Oracle создаст индекс для столбца(ов) ключа если ещё не существует такого индекса.
Ограничение по уникальности (unique constraint) тоже требует создание индекса. Это ограничение отличается от первичного ключа тем что значение в столбцах ограничения по уникальности могут быть NULL в отличие от первичного ключа, но это не влияет на создание и исопльзование индекса. Внешний ключ (foreign key) соблюдается с помощью индексов, но обязательным является индекс только на родительской таблице. Внешний ключ дочерней таблицы зависит от столбца первичного ключа или уникального ключа родительской таблицы. Когда строка добавляется в дочернюю таблицу, Oracle будет использовать индекс родительской таблицы для проверки существует ли такое значение в родительной таблице или нет, перед тем как позволить записать данные. Как бы то ни было желательно всегда создавать индексы для столбцов дочерней таблицы используемых как внешние ключи из соображений производительности: DELETE для родительской таблицы будет гораздо б ыстрее если Oracle сможет использовать индекс для проверки существуют ли ещё строки в дочерней таблице с этим значением или нет.
Индексы критически важны для производительности. Когда выполняется команда SELECT с директивой WHERE, Oracle необходимо определить строки в таблице которые необходимо выбрать. Если не создано индексов для столбцов используемых в директиве WHERE, то единственным способом сделать это – это вычитать всю таблицу (full table scan).Full table scan проверяют все строки по очереди для поиска нужных значений. Если в таблицы хранятся миллиарды строк, это может занять несколько часов. Если существует индекс для использованного в WHERE столбца, Oracle может искать используя индекс. Индекс это отсортированный список ключей значений структурирвоанных таким образом чтобы операция поиска была очень быстрой. Каждая запись это сслыка на строку в таблице. Поиск строк используя индекс гораздо быстрее чем чтение всей таблицы если размер таблицы больше определённого размера и пропорция между данными которые нужны для запроса и всеми данными в таблице ниже определённого значения. Для маленьких таблиц, или где секция WHERE всё равно выберет большую часть строк из таблицы, полное чтение таблицы будет быстрее: вы можете (обычно) доверять Oracle при выборе решения использовать ли индекс. Это решение осуществляется на основании статистической информации собираемой о таблице и строках в ней.
Второй случай когда индексы могут увеличить производительность это сортировка. Команда SELECT c директивой ORDER BY, GROUP BY или ключевым словом UNION (и несколько других) обязана отсортировать строки в определённом порядке – если не создан индекс, который может вернуть строки без необходимости в сортировке (строки уже отсортированы).
И третий случай это объекдинение таблиц, но опять же у Oracle есть выбор: в зависимости от размера таблиц и наличия свободной памяти, может быть быстрее вычитать таблицы в память и объединять их чем использовать индексы. Метод nested loop join читает строки одной таблицы и использует индекс другой таблицы для поиска совпадений (это обычно нагружает диск). Hash join считывает таблицу в память, преобразует в хеш таблицу и использует специальный алгоритм для поиска совпадений — такая операция требует больше оперативной памяти и процессорного времени. Sort merge join сортиует таблицы по значениям столбца для объединения и затем объединяет их вместе – это компромисс между использованием диска, памятии процессора. Если нет индексов –Oracle сильно ограничен в способах объединения.
https://habrahabr.ru/company/mailru/blog/266811/ кому интерестно – рекомендую почитать
TIP
Indexes assist SELECT statements, and also any UPDATE, DELETE, or MERGE statements that use a WHERE clause—but they will slow down INSERT statements.
Типы индексов
Oracle поддерживает несколько типов индексов с различными вариациями. Два типа, которые мы рассмотрим это B* Tree индекс, который является типом по умолчанию и bitmap индекс. Основное правило – индексы увеличивают производительность для чтения данных но замедляют при DML операциях. Это происходит потому что индексы нужно обновлять и поддерживать. Каждый раз когда строка записывается в таблицу, новый ключ должен быть вставлен в каждый индекс таблицы, что усиливает нагрузку на БД. Поэтому OLTP системы обычно используют минимальное количество индексов (возможно только необходимые для ограничений) а для OLAP систем создаётся столько индексов сколько нужно для быстроты выполнения.
B* Tree индексы (B*=balanced)
Индекс это древовидная (tree) структура. «Корень» (root) дерева содержит указатели на множество узлов второго уровня, которые в свою очередь могут хранить указатели на узлы третьего уровня и так далее. Глубина дерева определяется длинной ключа и количеством строк в таблице.
TIP
The B*Tree structure is very efficient. If the depth is greater than three or four, then either the index keys are very long or the table has billions of rows. If neither if these is the case, then the index is in need of a rebuild.
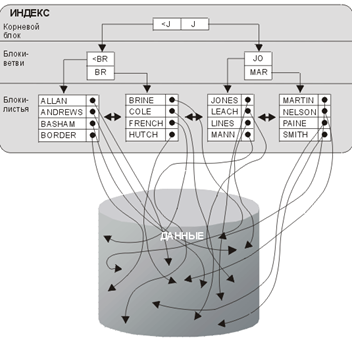
В листьях (узлы нижнего уровня) индекса хранятся значения столбца строк по порядку и указатель на строку. Также листья хранят ссылки на соседние листья. Таким образом чтобы выбрать строку если условие WHERE использует строгое равенство — Oracle исдёт по дереву в лист содержащий искомое значение и затем использует указатель для считывания строки.Если же используется нестрогое равенство (например LIKE, BETWEEN и т.д.) то вначале находится первая строка удовлетворяющая условию а затем считываются строки по порядку и переход между листьями осуществляется напрямую, без нового обхода по дереву.
Указатель на строку – это rowid. Rowid — это псевдостолбец закрытого формата, который имеет каждая строка в каждой таблице. Внутри значения зашифрован указатель на физический адрес строки. Так как rowid не является частью стандарта SQL то он не видим при написании обычных запросов. Но вы можете выбирать эти значения и использовать их при необходимости. Это отображено на рисунке 7-3.
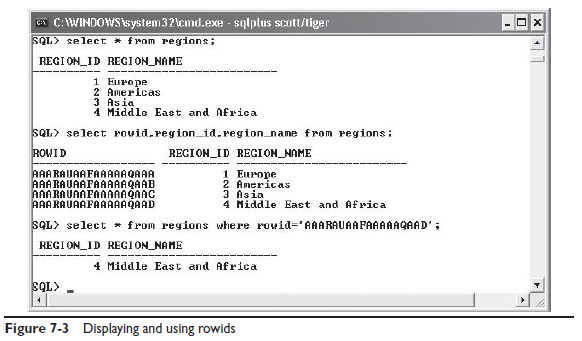
Rowid для каждой строки полностью уникальный. Каждая строка во всей БД имеет свой уникальный rowid. Расшифровав rowid получаем физический адрес строки, и Oracle может рассчитать в каком файле и где внутри файла находится искомая строка.
B* Tree индексы очень эффективны для вычитки строк число которых невелико относительно всех строк таблицы и таблица достаточно большая. Рассмотрим запрос
select count(*) from employees where last_name between ‘A%’ and ‘Z%’;
При использовании такого условия в WHERE запрос вернёт все строки таблицы. Использование индекса при таком запросе будет значительно медленее чем чтение всей таблицы. И вообще – вся таблица это то что нужно в этом запросе. Другим примером будет настолько маленькая таблица где одна операция чтения считывает её полностью; тогда нет смысла считывать вначале индекс. Обычно говорят что запросы, результат которых предполагает вычитку более чем 2-4% данных в таблице обычно работают быстрее используя полное чтение таблицы. Особым случаем является значение NULL в столбце указанном в секции WHERE. Значение NULL не хранится в B* Tree индексах и запросы типа
select * from employees where last_name is null;
всегд будут использовать полное чтение. Немного смысла создавать B* Tree индекс для столбцов содержащих несколько уникальных значений, так как он не будет в достаточной степени селективным: количество строк для каждого уникального значения будет слишком высоко относительно количества строк всей таблицы. В общем, B* Tree индексы полезно использовать если
Мощность (кратность – количество уникальных значений) столбца велика и
Количество строк в таблице большое и
Столбец используется в директивах WHERE и операциях объединения
Bitmap индексы
Во многих приложения природа данных и запросы таковы что использование B* Tree индексов не сильно помогает. Расммотрим пример. Есть таблица продаж, в которой набор данных о продажах в супермаркетах за год, которые нужно проанализировать в нескольких измерениях. На рисунке 7-4 показана простая диаграмма сущность-связь для четырёх измерений.
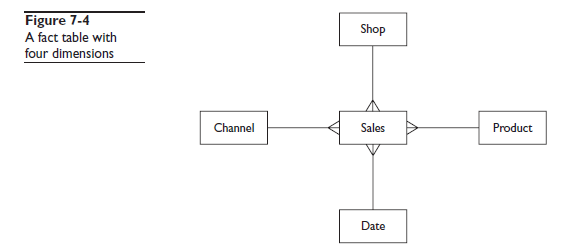
Мощность каждого измерения очень низкая. Преположим

Всего два измерения (DATE и PRODUCT) предполагают селективность лучше чем упомянутые 2-4%, т.е. делают использование индексов оправданным. Но если запросы используют предикаты группы (к примеру месяц в году, или группа товаров в которую входит десять товаров) то и эти измерения не подходят к требованиям. Отсюда следует простой факт: B* Tree индексы часто бесполезны в хранилищах данных. Типичным запросов может быть сравнение продаж между двумя магазинами приходящим покупателям определённой группы товаров за месяц. Можно создать B* Tree индесы для этих столбцов но Oracle проигнорирует их так как они недостаточно селективны. Для таких ситуация созданы bitmap индексы. Bitmap индексы хранят все rowid строк как битовую маску для каждого уникального значения ключа. Битовые маски индекса для измерения CHANNEL может быть к примеру

Это значит что первые две строки были приходящими покупателями, затем покупка с доставкой и т.д
Битовые маски индекса столбца SHOP могут быть

Это значит что первые две продажи были в Лондоне, затем одна в Оксфорде, затем четвертая в Рединге и так далее.
Теперь если приходит запрос
select count(*) from sqles where channel=’WALK-IN’ and shop=’OXFORD’
Oracle может выбрать две битовые маски и объединить их с помощью операции И

Результат логического И показывает что только седьмая и шестнадцатая строки удовлетворяют запросу. Операции над битовыми масками очень быстрые и могут использоваться для сложных булевых операций надо многими столбцами со многими сочетаниями И, ИЛИ или НЕ. Также достоинством bitmap индексов является то, что они хранят значения NULL. С точки зрения битовой маски – NULL просто ещё одно уникальное значение со своей битовой маской.
В общем, bitmap индексы полезны когда
Мощность столбца низкая и
Количество строк в таблице большое и
Столбец используется в операциях булевой алгебры
TIP
If you knew in advance what the queries would be, then you could build B*Tree indexes that would work, such as a composite index on SHOP and CHANNEL. But usually you don’t know, which is where the dynamic merging of bitmaps gives great flexibility.
Свойства индексов
Всего доступно шесть свойств которые можно применить при создании индекса
- Уникальность / Unique или nonunique
- Реверсивность / Reverse key
- Сжатие / Compessed
- Составной или нет /Composite
- Основанный на функции или нет / Function based
- Сортировка по возрастанию или убыванию / Ascending или descending
Все шесть свойств можно применить к B* Tree индексам и только три последних можно использовать для bitmap индексов.
Уникальный индекс не позволит дублировать значение. По умолчанию значение nonunique. Свойство уникальности индекса не связано с ограниченями уникальности или первичного ключа: если существует уникальный индекс то вствка дубликатов невозможно даже при отстуствии ограничения уникальности.
Реверсивный индекс строится на значениях ключа в которых байты строятся в обратном порядке: вместо индексирования значения к примеру ‘John’ будет использоваться значение ‘nhoJ’. Когда выполнится команда SELECT, Oracle автоматически преобразует строку поиска. Это используется для распределения строк по индексу в мультипользовательских системах. Например если много пользователей добавляют много строк в таблицу с первичным ключом как последовательно-увеличивающийся номер – все строки будут стремиться к концу индекса. Путем реверса ключа строки распределяются по всему индексу. При использовании индекса с реверсированным ключом базы данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.
Индексы со сжатием хранят повторяющееся значение ключа один раз. По умолчанию сжатие выключено, что значит если значение ключа не уникально то оно будет хранится для каждого повторения. Сжатый же индекс будет храние значение ключа один раз, а затем строку со всеми rowid строк с этим значением.
Составной индекс – это индекс который строится для нескольких столбцов. Нет ограничений на использование столбцов разных типов данных. Если условие WHERE не использует все столбцы, то индекс всё ещё может быть использован, но если не используется самый левый столбец, то Oracle использует skip-scanning метод который гораздо менее эффективный чем если бы левый столбец был включен.
Основанный на функции индекс строится для результата выполнения функции к одному или нескольким столбцам, к примеру upper(last_name или to_char(startdate,’ccyy-mm-dd’). Запросы должны использовать ту же функцию для поиска или Oracle не сможет использовать индекс.
По умолчанию индексы отсортированы по возрастанию (ascending), т.е. значения ключа хранятся от меньшего к большему. Режим по убыванию (descending) меняет это на противоположное. Фактически эта разница не очень важна: записи в индексе хранятся как двойной связный список т.е. можно переходить вверх или вниз с одинаковой скоростью, однако это повлияет на порядок строк в результате.
Создание и использование индексов
Индексы создаются неявно при создании ограничений первичного ключа или уникальности если индексы на соответствующих столбцах ещё не существуют. Синтаксис для явного создания индекса
CREATE [UNIQUE | BITMAP] INDEX [ schema.]indexname
ON [schema.]tablename (column [, column…] ) ;
По умолчанию индекс не уникальный, без сжатия, не-реверсивный типа B* Tree. Невозможно создать уникальный битмап индекс (и не стоит этого поделать если вы подумаете об этом с точки зрения свойства селективности). Индексы это объекты схемы и возможно создать индекс в одной схеме и таблицу в другой, но большинство людей найдут такой способ странным. Составной индекс – это индекс для нескольких столбцов. Составные индексы могут быть созданы для столбцов разных типов и столбцы не обязательно следовать друг за другом.
TIP
Many database administrators do not consider it good practice to rely on implicit index creation. If the indexes are created explicitly, the creator has full control over the characteristics of the index, which can make it easier for theDBA to manage subsequently.
Рассмотрим пример создания таблиц, индексов и затем определение ограничений
create table dept(deptno number,dname varchar2(10));
create table emp(empno number, surname varchar2(10),
forename varchar2(10), dob date, deptno number);
create unique index dept_i1 on dept(deptno);
create unique index emp_i1 on emp(empno);
create index emp_i2 on emp(surname,forename);
create bitmap index emp_i3 on emp(deptno);
alter table dept add constraint dept_pk primary key (deptno);
alter table emp add constraint emp_pk primary key (empno);
alter table emp add constraint emp_fk
foreign key (deptno) references dept(deptno);
Первые два индекса помечены как UNIQUE, что значит нельзя добавить дубликат. Это не определяет ограничение, но на самом деле это не что иное. Третий индекс не UNIQUE и позволяет хранить дубликаты и это составной индекс для двух столбцов. Четвертый индекс – это bitmap индекс, так как ожидается что мощность столбца будет низкой.
Когда определяются два ограничения, Oracle определит уже существующие индексы и использует их для ограничений. Обратите внимание что индекс для DEPT.DEPTNO не даст выигрыш с точки зрения происзводительности, но он всё равно необходим для обеспечения ограничения первичного ключа.
После создания индексы работают абсолютно невидимо и автоматически. Перед выполнением SQL запроса, сервер Oracle оценит возможные пути выполнения. Некоторые способы будут использовать индексы, некоторые нет. Далее Oracle использует информацию которую он собирает автоматически о таблица и окружении для принятия решения какой способ предпочтителен.
TIP
The Oracle server should make the best decision about index use, but if it is getting it wrong, it is possible for a programmer to embed instructions, known as optimizer hints, in code that will force the use (or not) of certain indexes
Изменение и удаление индексов
Команда ALTER INDEX не может менять свойства индексов интересных с точки зрения программиста: тип, столбцы и всё иное. ALTER INDEX создана для администратора БД и обычно будет использоваться для управления физическими свойствами индекса. Если необходимо изменить логические свойства – то единственным способом будет удаление старого индекса и создание нового. К примеру чтобы изменить индекс EMP_I2 можно выполнить следующие команды
drop index emp_i2;
create index emp_i2 on emp(surname,forename,dob);
Когда удаляется таблица, все индексы и ограничения для этой таблицы удаляются автоматически. Если индекс был создан неявно, то удаление ограничения приведёт к удалению индекса. Если вначале был явно создан индекс, а затем создавалось ограничение использующее этот индекс, то при удалении ограничения индекс остаётся.
















