Обзор табличных пространств (tablespace) и файлов данных
Мы рассмотрели процесс взаимодействия экземпляра и сессий: процессы и структуры памяти. В этой главе мы будем рассмотривать саму БД. Все процессы обработки информации происходят в памяти экземпляра БД, но хранение данных происходит в файлах базы данных на диске. База данных состоит из трех типов файлов: файл контроля, файлы логов и файлов даных. Данные хранятся в файлах данных.
Пользователи никогда не видят физический файл данных. Они видят логические сегменты. Системные администраторы ничего не знают о логических сегментах – они видят файлы. В базе данных Oracle физическая структура абстрагирована от логической. Это одно из требования парадигмы реляционных баз данных. Как DBA вы должны знать связь между логической и физической структурой БД. Мониторинг и администрирование этих структур – задача часто называемая как управление пространством (space management) является большой частью работы DBA. Средства предусмотренные в последних версиях БД могут автоматизировать задачу управления пространством в определенной степени, и они безусловно позволяют DBA настроить хранилище таким образом, чтобы максимально облегчить задачу обслуживания сервера.
Данные логически хранятся в сегментах (обычно таблицах), физически в файлах данных. Табличное пространтсво абстрагирует эти два понятия: в одном табличном пространтсве может храниться несколько сегментов и состоять из нескольких файлов данных. Нету прямой взаимосвязи между сегментом и файлом данных. Файлы данных могуть быть как файлами в файловой системе или (начиная с версии 10g) устройствами Automatic Storage Management (ASM).
Модель хранения данных Oracle
Разделение логической и физической структур является необходимой частю парадигмы реляционных баз данных. Парадигма гласит что программисты должны работать только с логическими структурами и позволять базе данных управлять их соответствием физическим структурам. Это значит что физическая структура может быть преобразована, или к примеру целиком база данных переведена на новое аппаратное обеспечение и операционную системы, а на работу приложений это не должно оказывать никакого влияния.
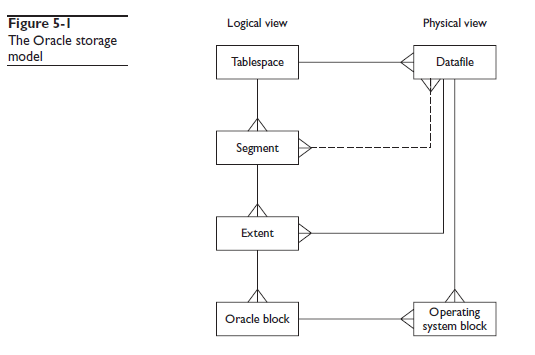
На рисунке 5-1 отображена модель Oracle как диаграмма сущность-связь, с логическими структурами слева и физическими структурами справа.
На этом рисунке одна линия связи отображена пунктирной линией: связь многие-ко-многим между сегментами и файлами данных. Эта линия выделена пунктиром, так как её не должно быть, отношение многие-ко-многим не допускаются хорошими DBA. Преобразование этой взаимосвязи к нормализованному виду и есть задача организации модели хранения.
Введение сущности табличное пространство (tablespace) разрешает взаимосвязь многие-ко-многим между сегментами и файлами данных. Одно табличное пространство может содержать несколько сегментов и состоять из нескольких файлов данных. Т.е. один сегмент может быть разделён между многими файлами данных, и один файл данных может содержать данные разных сегментов. Это решает много проблем организации хранения данных. В некоторых более старых РСУБД использовалась связь один-к-одному между сегментом и файлом данных: каждая таблица или индекс хранилась как отдельный файл. Это вызывало две большие проблемы для больших систем.
Во первых, в приложении могут использоваться тысячи таблиц и ещё больше индексов; управление тысячами файлов нелёгкая задача для системных администраторов. Во вторых, максимальный размер таблицы ограничен максимальным размером файла. Даже в современных ОС в которых нет ограничений по размеру файла – могут возникнуть проблемы из-за ограничений на аппаратном уровне. Использование табличных пространств решает обе эти проблемы. Табличным пространствам в базе данных присваиваются уникальные имена. Сущность сегмент (segment) представляет собой любой объект базы данных который хранит информаци и таким образом нуждается в пространстве внутри табличного пространства. Типичным примеро сегмента является таблица, но существуют и другие типы сегментов, индексы и сегменты undo. Сегмент может хранится тоьлко в одном табличном пространстве, но само табличное пространство может быть разбитым между многими файлами, которые составляют это табличное пространство. Таким образом размер таблицы больше не ограничивается максимальным размером одного файла. Так как много сегментов могут использовать одно табличное пространство, то становится возможным иметь куда больше сегментов, чем файлов данных. Сегменты это объекты которые принадежат схеме и идентифицируются они именем сегмента с именем схемы-владельца. Программируемые объекты схемы (такие как PL/SQL процедуры, представления или последовательности) не являются сегментами: они не хранят данные и хранятся в словаре данных.
Блоки Oracle это базовая единица операций чтения и записи для базы данных. Файлы данных форматированны на последовательно пронумерованные блоки Oracle. Размер блока определяется для табличного пространства (в общем он един для всех табличных пространств в пределах базы данных), по умолчанию (версия 11g) используется значения 8Кб. Строка может занимать всего несколько сотен байт, поэтому внутри одного блока может хранится несколько строк, но когда сессия хочет получить строку, будет вычитываться целый блок с диска и помещаться в кэш буфера. Также если изменилось значение только одного столбца для одной строки в буфере кэша – DBWn перезапишет на диск весь блок в файл данных откуда он был считан затерев старый. Размер блока Oracle может быть от 2ух до 16 Кб на операционных системах Linux или Windows и до 32 Кб в некоторых других системах. Размер блока контролируется параметром DB_BLOCK_SIZE. После создания базы данных нельзя изменить значение этого параметра, так как он используется для форматирования файлов данных табличного пространства SYSTEM. Если позже оказалось что необходимо изменить значение этого параметра, единственным решением будет создать новую базу и скопировать в неё все из уже созданной. Блок внутри файла можно идентифицировать по его уникальному номеру.
Управление дисковым пространством по одному блоку за раз было бы очень трудоёмкой задачей, поэтому блоки группируются в экстенты (extent). Экстентом называется набор последовательных блоков внутри одного файла данных. Каждый сегмент состоит из одного или более экстентов, последовательно пронумерованных. Эти экстенты могут находиться в любом или во всех из доступных для табличного пространства файлов данных. Экстент можно идентифицировать как внутри сегмента (экстенты последовательно пронумерованы в пределах сегмента начиная с нуля) так и внутри файла данных (каждый сегмент находится только в одном файле данных, начиная с определённого блока Oracle).
Файл данных физически состоит из блоков операционной системы. Как структурированы блоки операционной системы внутри файла данных целиком зависит от файловой системы используемой операционной системой. Некоторые файловые системы имеют общеизвестные ограничения и поэтому не используются в современных системах (например старая файловая система MS-DOS FAT поддерживает файлы размером до 4 Гб и всего 512 файлов в одной директории). Большинство баз данных устанавливается на файловые системы без практических огранчений, такие как NTFS в Windows или ext3 в Linux. Альтернативой файловой системе является хранение файлов данных на raw device-ах или Automatic Storage Management (ASM).
Блок операционной системы это базовый элемент операция записи чтения для файловой системы. Если процесс хочет прочитать один байт с диска подсистема ввода-вывода всё равно считает системный блок целиком. Размер блока операционной системы можно настраивать на некоторых ОС (например когда форматируется диск под файловую систему NTFS можно указать размер блока от 512 байт до 64 Кб), но обычно системные администраторы оставляют значения по умолчанию (512 Б для NTFS и 1Кб для ext3). Вот почему обычно отношение между блоками Oracle и блоками ОС обычно один-ко-многим, как показано на рисунке 5-1. Ничего не мешает сделать размер блока ОС равным размеру блока Oracle если ваша операционная система позволяет сделать это. Единственная конфигурация которой стоит избегать это когда размер системного блока больше чем размер блока Oracle.
Сегменты, экстенты, блоки и строки
Данные хранятся в сегментах. Представление словаря данных DBA_SEGMENTS хранит инфомрацию обо всех сегментах в базе данных. Запрос ниже отображает все типы сегментов в простой БД

Рассмотрим эти сегменты:
- Таблица (Table) — это структура которая хранит строки данных. Несмотря на то что наиболее часто встречающийся сегмент это таблица, никогда нельзя путать таблицу и сегмент, и что существуют гораздо более сложеные в организации таблицы которые используют другой тип сегмента
- Индекс (Index) это сортированный список ключей-значений, каждая из которых зранит указатель ROWID на физическое расположение строки. ROWID определяет в каком блоке Orace какого файла данных находится строка, и номер строки внутри блока.
- TYPE2 UNDO Это сегменты undo которые хранят данные перед изменениями для обеспечения транзакционной целостности: отмены транзакий, целостности чтения данных и обеспечения изоляции
- ROLLBACK сегменты rollback не должны использоваться в нормальном режиме работы начиная с версии 9i. Начиная с версии 9i используется автоматическое управление отмены операций основанное на сегментах TYPE2 UNDO (или просто undo). Всегда будет существовать один rollback сегмент для поддержки транзакций в момент создания БД (так как в момент создания ещё не существуют undo сегменты) но он не должен использоваться после создания БД
- Партиция таблицы( TABLE PARTITION) Таблица может быть разбита на несколько партиций. Если это настроено, то каждая партиция будет отдельным сегментом, а сама партицированная таблица не будет сегментом: она будет существовать как итог всех партиций. Каждая партиция будет таблицей, отдельным сегментом. Так как каждый сегмент может быть в отдельном табличном пространстве, то появляется возможность разбить таблицу между несколькими табличными пространствами
- Партиция индекса (INDEX PARTITION) по умолчанию индекс это один сегмента, но индексы как и таблицы могут быть партицированы. Если вы партицируете таблицу, обычно необходимо также партицировать и индекс
- Сегменты больших объектов (LOBSEGMENT, LOBINDEX, LOB PARTITION) Если столбец объявлен с типом large object, тогда в таблице хранится только указатель на запись в отдельном сегменте где хранятся данные этого столбца. Большие объекты могут быть индексированы для более быстрого доступа к данным внутри объекта и партицированы
- Кластер (CLUSTER) это сегмент которых содержит несколько таблиц. В отличие от партицирования которое позволяет распределять таблицы между разными сегментами, кластеризация позволяет собрать много таблиц в один сегмент
- Вложенные таблицы (NESTED TABLE) Если столбец внутри таблицы объявлен как определяемый пользователем объект (user defined object) который в свою очередь содержит столбцы, то такие столбцы хранятся в одельном сегмента, как вложенная таблица.
Каждый сегмент состоит из одного или более экстентов. Когда сегмент создаётся, Oracle выделяет инициализационный экстент в указанном табличном пространстве. Когда данные будет добавлятся экстент будет заполняться, и Oracle выделит другой экстент, в том же табличном пространстве, но не обязательно в том же файле данных. Если вы знаете что сегменту понадобится больше дискового пространства, вы можете вручную выделить экстент для этого сегмента. На рисунке 5-2 показано как определить расположение сегмента. Вначале создаётся таблица HR.NEWTAB используя параметры по умолчанию. Затем результат выполнения запроса к DBA_EXTENTS отображает, что сегмент состоит из одного экстента с номером ноль. Этот экстент находится в файле номер четыре и занимает 8 блоков. Первый из восьми блоков имеет номер 1401. Разме экстента 64 Кб, что говорит о том что размер блока 8 Кб. Следующая команда указывает Oracle что необходимо выделить ещё один сегмент для этого сегмента несмотря на то что первый экстент ещё не заполнен. Следующий запрос отображает что номер нового экстента равено единице, файл данных также с номером четыре и блоки выделены сразу после блоков первого экстента.
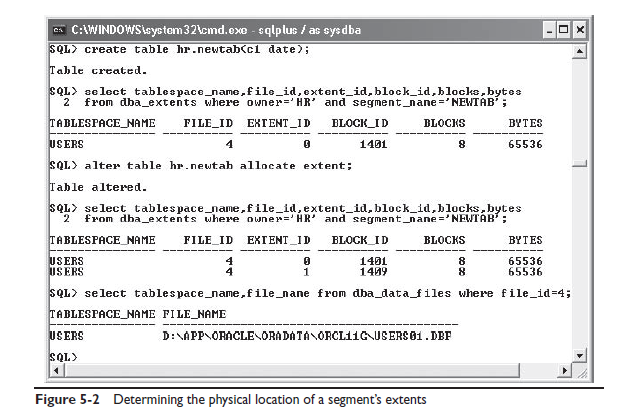
Отметим что из этого примера не совсем понятно из скольки файлов состоит табличное пространство, потому что алгоритм выбора файла для создания следующего экстента не просто очередь. Если табличное пространство состоит из нескольких файлов данных вы может указать в каком конкретно файле выделить экстент используя следующий синтаксис
ALTER TABLE tablename ALLOCATE EXTENT STORAGE (DATAFILE ‘filename’);
Последний запрос на рисунке 5-2 обращается к представлению DBA_DATA_FILES для нахождения имени файла в котором был выделен экстент, и название табличного пространства которому принадлежит файл данных. Для определения табличного пространства таблицы также можно использовать представление DBA_SEGMENTS.
Экстент состоит из набора последовательно пронумерованных блоков. У каждого блока есть область заголовок и область данных. Область заголовка имеет не фиксированный размер и записывается от начала блока. Помимо прочего, заголовок содержит информацию о строках (откуда в блоке начинается каждая строка) и информацию о блокировках. Область данных заполняется с конца блока. Между этимя двумя областями может быть (или не быть) пустое место. Событиями которые приведут к увеличению области заголовка является вставка данны и блокировка строки. Область данных вначале пусткая и затем заполняется по мере того как записываются новые строки (или ключи индекса если это блок сегмента индекса). Пусте пространство будет фрагментировано по мере вставки, удаления и изменения (что может привести к изменение размера строки) строк, но это не важно так как все операции с данными производятся в кэше буфера. Фрагментированное пространство объединяется когда это необходимо, обычно перед записью блока назад в файл данных процессом DBWn.