Использование архитектуры Shared Server Architecture
Стандартная архитектура выделенного сервера требует чтобы listener создавал выделенный серверный процесс для каждого подключения к экземпляру БД. Эти серверные процессы существуют пока сессия не будет завершена. В Unix подобных ОС серверные процессы это обычные системные процессы; в Windows это потоки внутри одного процесса ORACLE.EXE. Такая архитектура не поддерживает масштабирование для поддержки большого количества процессов на некоторых платформах. Альтернативой является архитектура общего сервера, ранее известная как многопоточный сервер (MTS).
Содержание
Ограничения архитектуры выделенного сервера
Чем больше пользователей подключаеся к экземпляру БД, тем больше запускается серверных процессов. Это не проблема, так как Oracle продумал эту ситуацию. Listener может запустить столько процессов, сколько необходимо, несмотря на то что могут быть ограничения по скорости запуска сессий. Если происходит большое количество одновременных запросов на соединение – listener будет помещать их в очередь. Этого можно избежать запустив несколько listener-ов на разных портах и распределяя нагрузку между ними. Когда сессия установлена, PMON процесс может обслуживать сколько угодно сессий. Но операционная система может иметь ограничения на количество запущенных процессов, проблемы при операции context switch и работе с памятью.
Компьютер может выполнять только одну задачу в одим момент времени (если у вас SMP сервер, то тогда каждый процессов выполняет по одной задаче). Операционная система эмулирует параллельное выполнение используя алгоритм распределения тактов процессора между всему текущими задачами. Этот алгоритм, известный как алгоритм распределения времени (timeslicing или timesharing) используется для распределения циклов процессора между процессами для выполнения. Переключения процессора с выполнения одной задачи на другую называется операцией переключения контекста (context switch). Эти операции очень дорогостоящие для производительности: операционной системе необходимо выполнить много работы для восстановления состоянии процесса при его активации и сохранения состояния процесса который становится неактивным. Чем больше пользователей подключается к экземпляру БД, тем чаще будет происходить операция context switch. В зависимости от операционной системы это может привести к падению производительности вашего сервера. ОС мейнфреймов могут выполнять операцию context switch для десятков тысяч процессов безо всяких проблема, но более новые (и простые) операционные системы как Unix и Windows не слишком хороши при работе с тысячами (даже сотнями) одновременно запущенными процессами. Производительность падает так как большая часть вычислительной мощности тратится на управление операциями смены контекста, и малая часть остаётся для собственно выполнения работы.
Так же могут возникать проблемы с памятью при подключении новых и новых подключений. Сами по себе серверные процесса не представляют опасности, так как во всех современных ОС используется общая память для процесса запущенного больше чем один раз, т.е. запуск тысячи процессов потребляет столько же памяти сколько запуск одного процесса. А проблема кроется в program global area (PGA). PGA — это участок памяти выделяемый для каждого процесса для поддержки состояния сессии и выполнения такой работы как к примеру сортировка данных. PGA не может использовать общую память – в ней содержатся данные уникальные для каждой сессии. Во многих опреационных системах при отстутствии свободной памяти используется файл подкачки или разбитое место на диске и страницы из памяти записываются на диск для освобождения места для данных рабочего процесса. Когда данные которые записаны на диск опять нужны в памяти, снова неиспользуемые в текущий момент времени страницы памяти записываются на диск а нужные данные считываются с диска в освободившееся пространство. Если такие операции перекачки информации происходят часто – это катастрофически снижает производительность. Так как PGA выделяется для каждой сессии, то чем больше пользователей будет подключаться, тем чаще (при остуствии достаточного количества памяти) будут происходит эти операции перекачки данных из памяти на диск и обратно.
Таким образом в архитектуре выделенного сервера, производительность может падать если ваша операционная система не поддерживает большого количества одновременно работающих процессов и проблемы могут усугубляться при отсутствии достаточного количества памяти. Надо отметить что на самом деле не важна активность подключенных сессий. Даже для неактивных сессий процесс создан и операционная система будет переключаться на эти процессы и перекачивать данные при необходимости согласно алгоиртму разделения времени. И тогда наступает момент что как бы вы не улучшали аппаратные средства, производительность начинает падать из-за неэффективности операционной системы при управлении операциями context switch и памятью. Для преодоления этих ограничений Oracle предлагает использовать архитектуру общего сервера (shared server architecture). Это позволяет обслуживать большое количество пользовательских процессов относительно небольшим количеством серверных процессов, и таким образом уменьшается количество процессов для управления операционной системой. Как дополнительный плюс уменьшается количество используемой памяти.
Надо помнить что потребность в архитектуре общего сервера очень сильно зависит от используемой платформы. Некоторые ОС не нуждаются в этом.
Архитектура общего сервера
Сразу необходимо отметстьи что архитектура общего сервера полностью реализуется на стороне сервера. Пользовательские процессы и программы не ощущают разницы при работе. Пользовательский процесс преобразует строку подключения в сетевой адрес listener-а и имя сервиса (или экземпляра) и посылает запрос к listener-у на подключение. Результатом подключения будет сетевой процесс. Этот процесс будет использоваться для отправки SQL запросов и получения результатов. Т.е. со стороны пользовательского процесса ничего не изменилось, всё так же как и в случае с выделенным сервером. Но серверная часть существенно отличается.
Архитектура общего сервера реализуется путём введения дополнительных процессов как части экземпляра БД. Это фоновые процесса запускаемые в момент запуска экземпляра. Эти процессы разделяют на два типа: диспетчеры и общие серверные процессы (dispatchers и shared servers process). Так же создаются дополнительные структуры памяти (очереди) в SGA и listener начинает работать немного по другому. Когда экземпляр БД настроен для запуска как общий сервер, в дополнение к обычным фоновым процессам запускается один или несколько процессов диспетчеров. Диспетчеры, так же как любые другие фоновые процессы, работают на определённом порту выделенном ОС: они могут взаимодействовать с listener-ом и регистрироваться, используя параметр БД local_listener для обнаружения настроенных listener-ов. Также запускается один или несколько общих серверных процессов (shared server process). Концептуально они ничем не отличаются в работе от обычных выделенных серверных процессов, но главное отличие это то что они не привязываются к одной конкретной сессии. Они получают SQL запросы, разбирают их и возвращают результат выполнения – но они не получают SQL запросы напрямую от пользовательских процессов. Эти процессы считывают их из очереди, которая формируется из запросов от любого количества пользовательских процессов. Подобным образом серверные процессы не возвращают результаты выполнения напрямую пользовательскому процессу – вместо этого, они кладут результат выполнения в очередь ответов. Возникает вопрос, как пользовательские запросы попадают в очередь для считывания серверным процессом и как результаты возвращаются пользователям? За это и ответственен диспетчер. Когда пользовательский процесс посылает запрос listener-у, вместо того чтобы создать серверный процесс и вернуть его адрес пользовательскому процессу, listener возвращает адрес диспетчера. Если создан только один диспетчер – listener подключит все входящие запросы к этому диспетчеру. Если созданы несколько диспетчеров – listener будет распределять входящие запросы на подключением между ними. Каждый пользовательский процесс думает что он взаимодействует с выделенным процессом, но это не так: диспетчер работает со многими пользовательскими процессами. Со стороны сети взаимодействие многих пользовательских процессов будет осуществляться по одному порту используемому диспетчером.
Когда пользователь запускает SQL запрос на выполнение он отсылается к диспетчеру. Диспетчер помещает все запросы в очерель. Эта очередь называется общей очерелью (common queue) так как её используют все диспетчеры. Вне зависимости к какому диспетчеру подключен пользовательский процесс все запросы помещаютяс в общую очередь. Все общие серверные процессы просматривают эту очередь. Когда запрос помещается в очередь – первый доступный серверный процесс забирает запрос. С точки зрения выполнения запроса происходит обычный цикл разбора-привязки-выполнения, но когда наступает этап выборки данных – серверный процесс не может отправить результат обратно пользовательскому процессу – между ними нет соединения. Вместо этого общий серверный процесс помещает результат выполнения в очередь ответов (response queue) которая принадлежит тому диспетчеру который получил этот запрос от пользовательского процесса. Каждый диспетчер просматривает свою очередь ответов, и когда результат готов, диспетчер заберёт его из очереди и отправит соответствующему пользовательскому процессу. На картинке 4-11 показано как три пользовательских процесса работают в архитектуре общего сервера. Пользовательские процессы 1 и 2 подключаются к экземпляру и назначаются диспетчеру 1, а пользовательский процесс 3 соединяется с диспетчером 2.
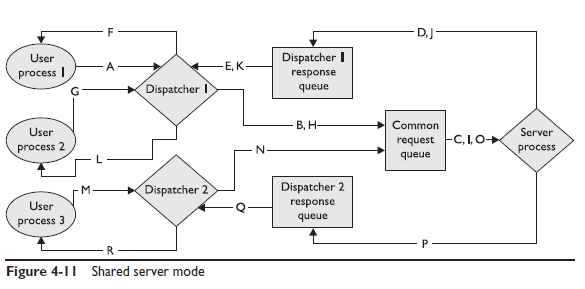
Результатом механизма диспетчеров и очередей является то что любой запрос любого пользовательского процесса может быть выполнен первым доступны общий серверным процессом. Всплывает вопрос как управляется состояние сессий. Пользовательский процесс вполне вероятно может выполнить команду SELECT FOR UPDATE, DELETE и COMMIT. В архитектуре выделенного сервера это не вызывает проблем, так как PGA ( привязанная именно к этой сессии) хранит информацию об активности сессии, и сервер знает какие изменения сохранить и какие блоки памяти разблокировать. PGA для сессии в архитектуре выделенного сервера хранит информацию о самой сессии, состояние курсоров, место для сортировки и состояние стека. В архитектуре общего сервера каждый запрос может выбираться из общей очереди разными серверными процессами, которые понятия не имеют о состоянии транзакции. Для преодоления этой проблемы, общие серверные процессы хранят информацию о сессиях в SGA вместо PGA. Таким образом когда бы серверный процесс не выбрал запрос на выполнение из общей очереди, этот процесс обратиться к соответствующем блоку в SGA и получит информацию о состоянии сессии. Область памяти в SGA используемая общими серверными сессиями называется общая пользовательская область (UGA user global area) и включает в себя всё что хранилось в PGA за исключением состояния стека. Вот откуда появляется экономия памяти. Oracle может управлять памятью в shared pool-е гораздо эффективнее чем во многих отдельных PGA. Часть SGA используемая для UGA – это large pool.
Настройка общего сервера
Так как архитектура общего сервера является особенностью только сервера, с клиентской стороны не нужна дополнительная настройка кроме создания файлов для Oracle Net (sqlnet.ora и tnsnames.ora). Со стороны сервера настройка требуется только для экземпляра БД. Listener автоматически подхватит конфигурацию shared server с помощью динамической регистрации. Таким образом shared server настраивается путём выставления соответствующих значений параметров инициализации экземпляра. Доступны несколько различных параметров, но два необходимых это: dispatchers и shared_servers.
Рассмотрим параметр shared_service. Этот параметр контролирует количество общих серверных процессов которые будут запущены в момент запуска экземпляра. Общие серверные процессы используют механизм очереди, но в идеальном случае очередь должна быть пустой: всегда должен быть доступен процесс для выполнения работы, которая появляется в общей очереди. То есть значение shared_servers должно быть установлено таким образом, чтобы быть равным предполагаемому количеству запросов выполняемых одновременно. Но если возникнет всплеск активности, Oracle динамически создат ещё процессы, количество которых ограничего значением параметра max_shared_servers. По умолчанию значение shared_servers равно единице если установлено значение переменной dispatchers. Если параметр max_shared_servers не установлено то используется значение по умолчанию равное одной восьмой от параметра processes.
Параметр dispatchers контролирует сколько диспетчеров запускать во время старта экземпляра и определяет их поведение. Это единственный обязательный параметр. Доступно много дополнительных опций, но две самые важные это: сколько процессов запускать и какой протокол использовать. Среди других опций доступны такие, которые позволяют устанавливать сетевой интерфейс и порт для диспетчеров, настраивать адреса listener-ов для регистрации и т.п. Параметр max_dispacthers устанавливает верхнюю границу количества допустимых для запуска диспетчеров, но этот параметр работает не так как max_shared_server. Oracle не будет сам автоматически запускать дополнительные процессы, но вы можете запустить вручную ещё процессы максимальным количеством не превышающим значение параметра max_dispatchers.
Рассмотрим пример настройки архитектуры общего сервера. Для этого достаточно выполнить команды
alter system set dispatchers=’(dispatchers=2)(protocol=tcp’;
alter system set shared_servers=20;
Настройка общего сервера очень важна. Всегда должно быть доступно достаточно общих серверных процессов для обработки запросов из общей очереди по мере их поступления и достаточно диспетчеров для обсуживания входящих запросов и возврата результатов обработанных запросов. При использовании архитектуры общего сервера необходимо контролировать потребление памяти общими серверными процессами в SGA. При переходе от выделенного сервера к общему размер SGA необходимо существенно увеличить.